v7.100.0.0 Breaking Changes: IncludeGraph
Starting with v7.100.0.0, the IncludeGraph for EF Core has been entirely rewritten, bringing about the following enhancements:
- Reduce Memory Consumption: The new
IncludeGraphcan reduce memory usage to around 20% of the memory its predecessor required, or even less. - Improve Performance: The new
IncludeGraphcan be up to 5 times faster, and potentially more so when dealing with a very high number of entities. - Elimination of Context Factory: The new
IncludeGraphno longer necessitates the configuration of a Context Factory for contexts that lack an empty constructor.
Projects that frequently use bulk operations will see additional benefits, as the memory collector now has fewer objects to dispose of, leading to an even greater reduction in memory footprint.
However, it's crucial to be aware that the new IncludeGraph comes with some breaking changes, detailed later in this document.
IMPORTANT: For those using IncludeGraph in their applications, we strongly advise thorough testing before updating your production environment.
LegacyIncludeGraph
For those who prefer the original IncludeGraph functionality from versions prior to v7.100.0.0, or encounter issues with the new version, the previous IncludeGraph has been renamed to LegacyIncludeGraph:
context.BulkInsert(list, options => {
options.LegacyIncludeGraph = true;
});
NOTE: Please ensure that you do not enable both IncludeGraph = true and LegacyIncludeGraph = true within the same bulk method. Opt for one or the other.
Memory & Performance Improvements
The revamped IncludeGraph offers a substantial reduction in memory consumption and significant performance enhancements across various scenarios.
These improvements are primarily due to minimizing the dependence of our library on certain EF Core methods. For instance, the LegacyIncludeGraph was generating commands similarly to the SaveChanges method, but the new IncludeGraph has been redesigned to generate commands in a more optimized manner. By reducing the number of commands generated, we've significantly reduced the memory footprint and simultaneously enhanced performance.
To demonstrate, consider a scenario with 2000 invoices and 10,000 invoice items:
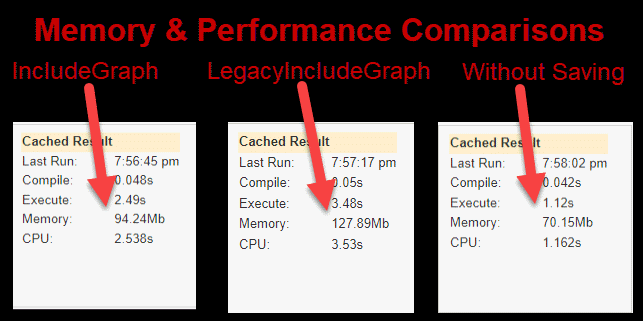
Though the improvement might seem marginal initially, the new IncludeGraph takes 94 MB, while the LegacyIncludeGraph takes 128 MB. However, if we remove the 70MB required to create the context and entities but not related to this option, it means that the IncludeGraph takes only 24 MB while the LegacyIncludeGraph takes 58 MB. So the new IncludeGraph took only 40% of the memory compared to LegacyIncludeGraph and the difference becomes even more noticeable as the number of entities rises.
In addition, the improvement in the performance was twice as fast which is another benefit of the new IncludeGraph.
Due to .NET Fiddle's memory constraints, we cannot showcase examples with a larger number of entities online. However, based on our tests, here's what you can expect:
10k invoices, 50k InvoiceItem:
| IncludeGraph | LegacyIncludeGraph | SaveChanges | |
|---|---|---|---|
| Memory | 60 MB | 220 MB | 200 MB |
| Performance | 1.5s | 5s | 6s |
100k invoices, 500k InvoiceItem:
| IncludeGraph | LegacyIncludeGraph | SaveChanges | |
|---|---|---|---|
| Memory | 400 MB | 2000 MB | 1800 MB |
| Performance | 10s | 48s | 58s |
From these observations, the LegacyIncludeGraph consumes marginally more memory compared to SaveChanges, but offers better performance.
The new IncludeGraph consumes around 20% of the memory that its predecessor did and can perform bulk operations 5 times faster. This memory savings can be even more significant in projects that often use bulk operations, as the garbage collector now has fewer objects to manage.
Limitations
- Does not yet support Table Splitting
- Does not yet support Entity Splitting
Breaking Changes
Default Value Handling
The primary breaking change in the new IncludeGraph relates to the handling of default values.
Consider the following example:
public static void Main() { List<Customer> customers = new List<Customer>(); customers.Add(new Customer { Name = "ZZZ Projects", MaximumRequestPerDay = 100 }); customers.Add(new Customer { Name = "Jonathan Magnan" }); } public class EntityContext : DbContext { protected override void OnModelCreating(ModelBuilder modelBuilder) { modelBuilder.Entity<Customer>().Property(x => x.MaximumRequestPerDay).HasDefaultValueSql("50"); base.OnModelCreating(modelBuilder); } public DbSet<Customer> Customers { get; set; } } public class Customer { public int CustomerID { get; set; } public string Name { get; set; } public int MaximumRequestPerDay { get; set; } }
In this example, we've set a default SQL value (50) for the MaximumRequestPerDay property of the Customer class. For the customer ZZZ Projects, we have set the MaximumRequestPerDay value to 100, and for the customer Jonathan Magnan, we have not specified any value for the MaximumRequestPerDay property.
When the model is aware of a SQL default value, a method like BulkInsert(customers) will ignore the MaximumRequestPerDay property during insertion, regardless of whether a value has been specified. It will always let the database use the default value.
With the LegacyIncludeGraph option, the behavior was different. This option relied on EF Core to generate commands, which already handled this scenario perfectly by treating the two entities as two separate inserts as they have different behavior. Which means, that an insert will be used for entities that have a value specified (ZZZ Projects have the value 100), and an insert is created for entities that have no value that will ignore the MaximumRequestPerDay property (*Jonathan Magnan have no value specified). However, this came at the cost of greater memory consumption and reduced performance.
The new IncludeGraph option now generates the command itself, behaving the same way as when no option is specified. This means it will ignore the MaximumRequestPerDay property during insertion, regardless of whether a value has been provided.
To force the use of values from the entity, you can utilize the ForceValueGeneratedStrategy option:
context.BulkInsert(list, options => {
options.IncludeGraph = true;
// if you want all types to use the same strategy
// options.ForceValueGeneratedStrategy = Z.EntityFramework.Extensions.ValueGeneratedStrategyType.OnAdd;
options.IncludeGraphOperationBuilder = builder =>
{
if(builder is Z.BulkOperations.BulkOperation<Customer> bulk)
{
// if you want specific type to use this strategy
bulk.ForceValueGeneratedStrategy = Z.EntityFramework.Extensions.ValueGeneratedStrategyType.OnAdd;
}
};
});
If your insert requires both behaviors, we recommend continuing to use the LegacyIncludeGraph option.
For a clearer understanding, examine the following examples and their outputs:
- DefaultValueSql + Without Options
- DefaultValueSql + LegacyIncludeGraph
- DefaultValueSql + IncludeGraph
- DefaultValueSql + IncludeGraph + ValueGeneratedStrategyType.OnAdd
Handling Duplicate Entities in a List
Consider the following example:
public class Customer { public int CustomerID { get; set; } public string Name { get; set; } } List<Customer> customers = new List<Customer>(); var duplicate = new Customer { Name = "ZZZ Projects" }; // Add it twice customers.Add(duplicate); customers.Add(duplicate);
In this case, the same customer has been added twice to the customers list. Depending on how you use BulkInsert, different behaviors will manifest:
- BulkInsert: The same customer will be inserted twice.
- BulkInsert + IncludeGraph: An exception will be thrown. Duplicate entities are not permitted with the new
IncludeGraph. - BulkInsert + LegacyIncludeGraph: The customer will only be inserted once. The graph identifies the entity as identical within the list and prevents duplicate insertions.
The behavior described above for IncludeGraph applies only to the top-level entity (Customer). Any entities found within the graph will be added only once if they are the same instance.
Handling Duplicate Key on Root
Consider the following example:
public class Customer { public int CustomerID { get; set; } public string Name { get; set; } } List<Customer> customers = new List<Customer>(); customers.Add(new Customer { CustomerID = 1, Name = "ZZZ Projects" }); customers.Add(new Customer { CustomerID = 1, Name = "Jonathan Magnan" });
In this scenario, different customers have been added, but they share the same key in the customers list. Depending on your BulkInsert configuration, different behaviors will emerge:
- BulkInsert: SQL Server will throw the error: 'Violation of PRIMARY KEY constraint 'PK_Customers'. Cannot insert duplicate key in object 'dbo.Customers'. The duplicate key value is (1).'
- BulkInsert + IncludeGraph: SQL Server will throw the error: 'Violation of PRIMARY KEY constraint 'PK_Customers'. Cannot insert duplicate key in object 'dbo.Customers'. The duplicate key value is (1).'
- BulkInsert + LegacyIncludeGraph: The EF Core tracking will throw the error: 'The instance of entity type 'Customer' cannot be tracked because another instance with the same key value for {'CustomerID'} is already being tracked'
Handling Duplicate Key in Graph
Consider the following example:
public class Invoice { public int ID { get; set; } public int ColumnInt { get; set; } public InvoiceItem Item1 { get; set; } public InvoiceItem Item2 { get; set; } } public class InvoiceItem { public int ID { get; set; } public int ColumnInt { get; set; } } var invoice = new Invoice() { ColumnInt = 1 }; var itemX = new InvoiceItem() { ID = 1, ColumnInt = 2 }; var itemY = new InvoiceItem() { ID = 1, ColumnInt = 3 }; invoice.Item1 = itemX; invoice.Item2 = itemY;
In this scenario, the invoice has been added with 2 different InvoiceItem objects that have the same ID.
Due to how context.Add(invoice); functions, the ChangeTracker will update Item2 to overwrite its value with ItemX. In more detail:
- The
ChangeTrackeradds theinvoicefor tracking. - When adding
itemX, theChangeTrackerchecks if anInvoiceItemalready exists with this key. Since the answer isno, it adds it for tracking. - When adding
itemY, theChangeTrackerchecks if anInvoiceItemalready exists with this key. Since the answer isyes, it updates the reference ofItem2toitemX.
In this situation, different behaviors will occur:
- SaveChanges: The invoice and
itemXwill be inserted. TheitemYwill not be saved. - BulkSaveChanges: The invoice and
itemXwill be inserted. TheitemYwill not be saved. This follows the same behavior asSaveChanges. - BulkInsert + IncludeGraph: SQL Server will show the error: 'Violation of PRIMARY KEY constraint 'PK_InvoiceItems'. Cannot insert duplicate key in object 'dbo.InvoiceItems'. The duplicate key value is (1).'
- BulkInsert + LegacyIncludeGraph: The invoice and
itemXwill be inserted. This follows the same behavior asSaveChanges.
For BulkInsert, we assumed that the ID is always inserted or the option InsertKeepIdentity is true.
ZZZ Projects